
")

Autor: Frank Scheller
„Heureka, endlich wissen wir was zu tun ist.” So oder so ähnlich euphorisch hallt es früher oder später durch so ziemlich jede Softwarefirma.
Ganz egal wie groß diese auch sein mag, irgendwann stellt irgendjemand fest, dass es doch eine grandiose Idee wäre, die Software komplett automatisch zu testen. Am besten auch noch sehr kundennah. Ein Rundumschlag in Sachen Qualitätssicherung steht an und neben den bereits vorhandenen Unittests sollen nun auch noch automatische Oberflächentests erstellt werden.
Dies – so scheint es – ist so einfach und effektiv, dass jedem Entwickler und Tester vor Glück die Star Trek Figuren vom Schreibtisch purzeln. „Außenteam an Brücke: Wir beamen rüber! Unsere Arbeit hier ist erledigt.” Solltet ihr zu den Testern und Entwicklern gehören, die jeden Tag auf eine ganze Reihe Oberflächen-Testläufe schauen, von denen ab und zu mal einer fehlschlägt und deren Fehlschlagen sofort auf einen Fehler in der Software hindeutet, dann braucht ihr jetzt nicht weiterlesen. Ihr könnt euch in euer Testschlaraffenland zurückziehen und fußwippend im Takt zu einem Genesis Song im Internet surfen. Ihr seid angekommen. Glückwunsch.
„NON OMNIBUS UNUM EST QUOD PLACET“ – ES GIBT NICHTS, WAS ALLEN GEFÄLLT
Alle anderen aber mal bitte kurz tief durchatmen und ganz genau hinhören: So einfach ist das leider alles nicht! Und dabei meine ich gar nicht die Validierung des richtigen Automatisierungswerkzeuges. Das geht in der Regel in ein paar Schritten, die sich meist so anhören:
- „Ach wir nehmen einfach ein Capture and Reply Tool. Das geht schnell, ist leicht zu bedienen und stabil. Da gibt es ja auch genug am Markt. Und günstig sind die auch. Ein Traum.“
- „Capture and Reply läuft nicht so rund. Immer diese Ausfälle, wenn sich mal etwas an der Oberfläche ändert. Kein Wunder, dass die so günstig sind. Da muss es doch auch was Anderes geben.“
- „Wir haben doch eine Weboberfläche, wir nehmen Selenium oder ein anderes Framework. Das ist super, damit packen wir den Stier bei den Hörnern.“
- „Selenium etc. ist gar nicht so einfach. Nicht jeder Tester kann damit einfach losskripten. Wir bauen einfach eine eigene Testautomatisierung. Mit eigenen Keywords. Basierend auf den vorhandenen Frameworks. Auf so eine geniale Idee ist noch niemand gekommen.“
Wenn euch diese Sätze bekannt vorkommen, dann seid ihr keine Gefangenen in einem temporären Fragment, sondern mitten drin in der wunderbaren Welt der Oberflächen-Testautomatisierung. In dieser Welt wird viel selbst gebaut und jeder kocht sein eigenes kleines Süppchen, das leider am Ende runtergewürgt werden muss.
“NIL ADMIRARI – SICH ÜBER NICHTS WUNDERN”
Ein Kernproblem jeder Oberflächen-Testautomatisierung, welches die Suppe nämlich gehörig versalzt, ist in ganz vielen Fällen die Testumgebung. Viele Testläufe werden gerne nachts auf virtuellen Maschinen (VM) ausgeführt. Da stören sie nicht den normalen Betrieb und verbrauchen keine Ressourcen, die man für das Tagesgeschäft benötigt.
Zwei gängige Setups bei der Erstellung von Testumgebungen für die automatischen Oberflächentests sehen wie in Abb. 1 aus:

Hier gibt es natürlich noch unzählige verschiedene Varianten, aber in den letzten Jahren bin ich diesen am meisten begegnet.
„BIS REPETITA NON PLACENT“ – WIEDERHOLUNGEN GEFALLEN NICHT
Je mehr Testfälle man bekommt, desto schneller stellt man allerdings fest, dass Testumgebungen gerne dazu neigen, sich einfach ohne große Worte sporadisch zu verabschieden.
Diese VMs fallen oft dadurch auf, dass viele Testfälle ROT oder gar keine Ergebnisse liefern. Je nach Testprozess-Setup. Bei genauerer Analyse stellt sich dann heraus, dass es ein Testumgebungsproblem in Form eines Absturzes einer oder mehrerer VMs gab. Das ist nicht nur ärgerlich, das kostet auch jede Menge Zeit und Geld. Und ein Satz, der im Test neben „gut gemacht“ nie fällt ist: „Lasst es ruhig angehen, Zeit und Geld haben wir im Überfluss.”
Je häufiger dieses Phänomen auftritt und die VMs gelegentlich abstürzen, umso unruhiger und unzufriedener werden die Tester, müssen sie doch viele Tests wiederholen und oft auch manuell nachprüfen.
„UT DESINT VIRES TAMEN EST LAUDANDA VOLUNTAS“ – WENN AUCH DIE KRÄFTE FEHLEN, DER WILLE IST DENNOCH ZU LOBEN
Und nun kommt ein Meeting, das viele Tester und Entwickler kennen dürften: Das „Was machen wir dagegen Meeting”. Ein Meeting, in dem beschlossen wird, dass alle Gründe für einen sporadischen VM-Absturz gesammelt werden sollen:
- An welcher Stelle treten die Abstürze meistens auf?
- Welche Prozesse sind beteiligt?
- Welche Keywords?
- Welche Teile der Software sind am meisten betroffen?
- Zu welcher Uhrzeit?
- Etc.
Eine wunderschöne Excel-Tabelle wird mit Leben befüllt und ist eigentlich schon tot bevor sie gespeichert wird. Einfach alles, was irgendwie mit den Abstürzen zu tun haben könnte, wird Treibjagdmäßig aus dem Gebüsch gelockt. Der Nutzen dieser Tabellen ist recht bescheiden. Es wird hin und wieder drauf geguckt, sie wird ab und an befüllt und ganz vielleicht werden auch mal ein bis zwei Probleme gelöst. Aber VM-Abstürze sind wie Herpes. Sie kommen ein Leben lang zurück.
Alle paar Wochen schreit irgendjemand laut auf, weil er glaubt, die Lösung aller Probleme gefunden zu haben. Es wurde irgendein Prozess in den tiefsten Tiefen des Kaninchenbaus gefunden, der wohl etwas mit den Abstürzen zu tun haben könnte. Meist wird dann einem Update-Prozess oder dem Virenscanner die Schuld gegeben. Aber die VM lässt sich nicht bezwingen. Sie hat ihre eigenen Regeln. Könnte sie sprechen, würde sie bestimmt so etwas sagen wie: „Hältst du es für möglich, dass mein Vorsprung an Kraft und Geschwindigkeit tatsächlich etwas mit meinen Muskeln zu tun hat – in diesem Raum? Denkst du, das ist Luft, die du gerade atmest?“ (Morpheus, The Matrix)
Testfälle, die aufgrund von Umgebungsproblemen fehlschlagen, bekommen meist auch einen Hinweis in der Auswertung. In meiner Laufbahn sind mir da unzählige Farben und Bezeichnungen untergekommen:
- TUP für Testumgebungsproblem mit der Farbe dunkelgrün in der Auswertungstabelle – passend zu jeder Jahreszeit.
- UF für Umgebungsfehler ohne Farbe in der Auswertungstabelle.
- VMF für VM-Fehler mit der Farbe lila in der Auswertungstabelle – wenn man es tragen kann, warum nicht.
- TW für Test wiederholen auch ohne Farbe in der Auswertungstabelle.
Gemein hatten sie auf jeden Fall alle eine Abkürzung, und das ist ja schon mal ein Anfang und zeigt, dass dieses Problem nicht nur vereinzelt Auftritt.
„FACTA, NON VERBA“ – TATEN, NICHT WORTE
Gibt es eine Lösung für diese abstürzenden VMs? Meiner Meinung nach nicht. Aber so einfach kann man es nicht sagen, denn wenn man es mal aus einer anderen Perspektive betrachtet, sind vielleicht gar nicht die vereinzelt abstürzenden VMs das große Problem, sondern der Prozess, wie man damit umgeht.
Viel Zeit geht bei der Testauswertung einfach verloren, weil die nicht ausgeführten oder fehlgeschlagenen Tests noch mal gestartet werden müssen. Meist passiert dies am nächsten Morgen, wenn erkannt wurde, welche Tests eigentlich fehlen. Der Tester begutachtet die Testfallergebnisse und stellt fest, dass von den 4.000 Tests ca. 200 nicht gelaufen sind. Bei der Analyse stellt sich heraus, dass es an einer oder mehreren abgestürzten VMs lag. Anschließend werden diese nicht gelaufenen Tests neu gestartet und man hat ein paar Stunden später ein zweites Ergebnis. Meistens sind diese Testfälle dann problemlos durchgelaufen.
Mit einer wachsenden Anzahl von Testfällen steigt auch die Anzahl der VM-Ausfälle. Aus meiner bisherigen Erfahrung fangen die Probleme ab dem 500. bis 800. Testfall an. Ab da treten die ersten Ausfälle auf. Sicherlich besteht auch ein enger Zusammenhang zwischen der Laufzeit der Testläufe und den Abstürzen.
Zurück zu der verschwendeten Zeit: Ein paar Änderungen am Testprozess und an der Automatisierung können erheblich dazu beitragen, dass die ungenutzte Testzeit in der Nacht, nachdem sich eine oder mehrere VMs mal wieder verabschiedet haben, nicht verschwendet wird.
„NON MULTA, SED MULTUM“ – NICHT VIELERLEI TREIBEN, SONDERN EINE SACHE INTENSIV UND GENAU

In der Luftfahrt gibt es die sogenannte FORDEC-Methode, die einem die strukturierte Entscheidungsfindung einfacher macht. FORDEC steht hierbei für: Facts, Options, Risks, Decision, Execution, Check.
Ob dieses Mittel nun die beste und eleganteste aller Lösungen ist, sei mal dahingestellt. Allerdings hilft es dabei, eine Entscheidung zu treffen und pragmatische schnelle Entscheidungen sind leider eine Seltenheit in der Software-Entwicklung. Mehrere Meetings mit möglichst vielen Teilnehmern scheinen begehrter, aber nicht unbedingt zielführender zu sein. In unserem speziellen Fall wäre dies eine angemessene schnelle FORDEC-Analyse zu der Problemstellung
„QUIDQUID PRAECIPIES, ESTO BREVIS“ – WAS AUCH IMMER DU LEHREN WIRST, FASSE DICH KURZ
Ein recht solider Prozess könnte so aussehen, wie in Abb. 2 dargestellt. Dazu einige Erläuterungen:
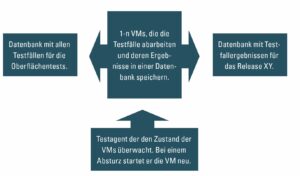
Testfall Datenbank
Es existiert eine Datenbank (DB) in der alle automatischen Oberflächentests enthalten sind. Als Beispiel ein einfacher DB Eintrag, bezogen auf den automatischen Oberflächentest eines Bankautomaten.
Das Feld Priorität ist zu einem späteren Zeitpunkt interessant, wenn es mal darum geht, dass aus Zeitmangel eventuell nicht alle Testfälle ausgeführt werden können. Reflexartig rufen die meisten Testbeteiligten dann nach einer Priorisierung. Und wenn man diese dann wie Copperfield aus dem Hut zaubern kann, liegen einem die IT-Herzen zu Füßen
Virtuelle Maschinen
Die VMs führen die Tests selbstständig durch. Sie prüfen auf der Datenbank, welche Testfälle noch ausstehen, führen diese aus und speichern das Ergebnis in die Datenbank der Testfallergebnisse. Hierfür ist unter Umständen ein kleines Tool nötig, das je nach Umgebung passend implementiert werden muss. Da es unzählige Testautomatisierungsumgebungen gibt, will ich es gar nicht konkretisieren.
Testagent
Dies ist das zentrale kleine Werkzeug für diesen Testprozess. Er überwacht den Zustand der VMs. Ob er sie nun regelmäßig „anpingt“ oder auf ein anderes Signal wartet, welches evtuell ein Agent auf der VM sendet, ist egal. Hauptsache, es gibt einen Testagenten, der mitbekommt, wenn eine VM nicht mehr ansprechbar und abgestürzt ist. Ist dies der Fall, startet der Agent die VM neu, so dass sie im Pool weiterhin ihre Testaktivität aufnehmen kann. Der Zustand, dass man erst weiß, ob die VM noch läuft, wenn man die Testergebnisse bekommt, ist somit vorbei. Schrödingers Katze würde nun einen Luftsprung machen.
Testfallergebnis Datenbank
In diese Datenbank schreibt das Testausführungswerkzeug der VM nach jedem Test das Ergebnis des Testfalls. Dies hat den Vorteil, dass man auch bei einem Absturz immer die Ergebnisse zentral vorliegen hat. Ein Abgleich aus der Ergebnistabelle und Testfallbestandstabelle lässt darauf schließen, welche Testfälle noch durchgeführt werden müssen. Jeder, der ein wenig Ahnung von Datenbanken hat, baut da schnell etwas Passendes zusammen.
„SIC PARVIS MAGNA“ – GROSSES AUS KLEINEN URSPRÜNGEN
Um diesen Prozess zu realisieren, gibt es natürlich ein paar Voraussetzungen, die erfüllt werden müssen. Eine der wichtigsten ist die Unabhängigkeit der Testfälle. Jeder Testfall sollte für sich allein lauffähig sein, ohne das Ergebnis des vorigen zu benötigen. Bei bestehenden Tests ist dies leider oft nicht der Fall. Gerade bei einer am Anfang stiefmütterlich behandelten Testbasis. „Hauptsache, wir haben Tests“, ist da oft die Devise.
Dies rächt sich allerdings mit steigender Testfallanzahl. Mein Rat ist da: Augen zu und durch. Testfälle umschreiben, anpassen und in dem Atemzug – wenn noch nicht vorhanden – auch in eine passende Datenbank aufnehmen. Die braucht man später sowieso noch. Jetzt wird ein Testagent implementiert, der den Zustand der VMs prüft und ggf. neu startet. Der Aufwand ist normalerweise recht gering. Etwas mehr Aufwand ist es allerdings, die bestehende Infrastruktur dahingehend umzubauen, dass die Testfälleeinzeln ausgeführt und die Ergebnisse SOFORT nach jeder Testdurchführung in eine Datenbank gespeichert werden.
Da jede Firma ein anderes Tooling verwendet, habe ich dafür keine Universallösung, aber auch dies ist mit ein paar Entwicklungsstunden erledigt. Das richtet sich natürlich nur an die Abteilungen, die ihre Automatisierung mit der heißen Nadel, ohne Rücksicht auf Verluste, selbst gestrickt haben. Ich habe die vier Schritte der Werkzeugfindung ja weiter oben schon erwähnt. Die Glücklichen, die bestehende Werkzeuge verwenden, müssen sich um das Thema eigentlich keine Sorgen machen. Sie können wieder mit den Füßen zu einem Genesis Song wackeln.
„FINIS CORONAT OPUS“ – DAS ENDE KRÖNT DAS WERK
Das ist nun alles sehr vereinfacht dargestellt und muss den Gegebenheiten jeder Firma neu angepasst werden, es gibt aber eine Idee eines möglichen robusteren Oberflächentestprozesses. Es bietet auch die Möglichkeit verschiedenster Erweiterungen. So können einzelne Testzeiten mit in die Ergebnisdatenbank gespeichert werden, um eventuell Hinweise auf eine Verlangsamung der Software zu bekommen. Auch eine automatische Priorisierung je nach Fehlerfindungsquote ist denkbar.
Sich erstmal mit dem Gedanken abzufinden, dass VMs abstürzen, mag einem im ersten Augenblick die Tränen in die Augen treiben, aber eigentlich ist es gar nicht so schlimm. Und ich sage auch nicht, dass man sich nicht hin und wieder mit den VM-Problemen beschäftigen sollte. Eventuell gibt es ja Absturzursachen, die man leicht beheben kann, aber im Sinne der schnellen Testauswertung und Analyse ist der beschriebene Prozess immerhin ein Anfang.
Abschließend rate ich aber jeder Oberflächentestabteilung, die ähnliche Probleme hat, folgendes: Anstatt unzählige Stunden in die Analyse des Problems der abstürzenden VMs zu investieren – passt den Prozess soweit an, dass dieses Problem händelbar wird. Oft ist die Testinfrastruktur schon vorhanden und allein der Wille zum Umdenken fehlt. Wenn ich dem einen oder anderen dahingehend also einen neuen Denkanstoß liefern konnte, hat es mich gefreut.

