


Autor:innen: Prof. Dr. Bruno Legeard, Dr. Anne Kramer
Continuous Integration, Continuous Deployment, DevOps – alles zielt darauf ab, schneller zu werden. Zu Recht, denn die Geschwindigkeit, mit der Software-Updates bereitgestellt werden, ist von strategischer Bedeutung für die Hersteller. Wir wollen der Konkurrenz zuvorkommen, die Kundenzufriedenheit steigern und schneller Erkenntnisse über die Marktakzeptanz erhalten. Gründe gibt es genug …
Hindernisse allerdings auch. Verschiedene Faktoren technischer, konzeptioneller oder organisatorischer Art bremsen den Prozess. Insbesondere die Akzeptanztests auf
Systemebene und die End-to-End-Tests sind aufwendig und werden deshalb kritisch beäugt. Wie viel davon ist wirklich nötig? Was ist der beste Kompromiss zwischen Reaktionsschnelligkeit und Qualität?
Was ist Usage-Driven Testing?
Usage-Driven Testing ist ein werkzeuggestützter Ansatz, der darauf abzielt, den Aufwand für die Erstellung dieser Tests zu reduzieren und gleichzeitig sicherzustellen, dass die automatisierten Testsuiten der tatsächlichen Nutzung des Produkts entsprechen. Denn Reaktivität und Qualität lassen sich durch diesen Shift-Right-Ansatz vereinen!
Der Balanceakt zwischen Reaktionsschnelligkeit und Qualität
Wenn wir schneller und häufiger neue Versionen ausrollen wollen, müssen wir unsere Tests automatisieren. Für Unit-Tests – bzw. Komponententests, wie sie laut ISTQB offiziell heißen – geht das vergleichsweise kostengünstig und schnell. Unit-Tests bilden daher die Basis der agilen Testpyramide. Sie sollten zahlreich und vollständig automatisiert sein, stärken sie doch im großen Maße das Vertrauen in die Qualität des Quellcodes.
End-to-End-Tests sind teurer und langsamer auszuführen. Sie stehen daher an der Spitze der Pyramide, was bedeutet, dass sie weniger zahlreich und tendenziell auch weniger automatisiert sind. Sie sind jedoch extrem wichtig, da sie ein Maß für das Vertrauen in die Funktionalität als Ganzes liefern und letztlich für eine gute Nutzererfahrung sorgen. Schließlich bringt es nichts, schnell zu liefern, wenn man aufgrund schlechter Qualität Kunden verliert.
Um Reaktionsschnelligkeit und Qualität miteinander zu vereinbaren, müssen wir einen Weg finden, wie wir die End-to-End-Tests ohne Verlust an Qualität auf das notwendige Minimum beschränken können. Anders ausgedrückt: Wir brauchen wenige, dafür aber fachlich relevante, idealerweise automatisiert durchführbare Tests, deren Erstellung und Pflege einfach und günstig ist.
Testen, was wirklich zählt
„Fachlich relevant“ – das sagt sich so einfach. Gemeint sind Tests, die der realen Nutzung des Produktes möglichst nahekommen. Zu Beginn der Entwicklung machen wir uns
daher Gedanken über Anwendungsfälle oder erstellen Story Maps. Diese dienen dann als Grundlage für die End-to-End-Tests. Einmal erstellt, werden die Tests regelmäßig durchgeführt und bei Bedarf angepasst. Da die Pflege aber, wie gesagt, erhebliche
Anstrengungen und Investitionen erfordert, rühren wir diese Tests nur dann an, wenn es absolut erforderlich ist.
Das führt dazu, dass die Tests mit der Zeit an Relevanz verlieren. Abläufe, die vor sechs Monaten noch einen Test wert waren, müssen heute nicht mehr der aktuellen Nutzung des Produkts durch die Nutzer entsprechen. Zum einen hat sich die Software weiterentwickelt, zum anderen lernen wir permanent hinzu. Nutzer verwenden unsere Produkte oft anders, als wir uns das am Anfang vorgestellt haben.
Abbildung 1 zeigt einen Ablauf, bei dem der Nutzer Funktionen verwendet, die der Tester überhaupt nicht auf dem Schirm hatte. Im schlimmsten Fall kommt es bei so einem unbekannten Ablauf zu Regressionen. Dies kann negative Auswirkungen auf unser Unternehmen und seinen Ruf haben. Schließlich arbeiten die Nutzer schon seit Längerem so (nur wussten wir das bislang nicht) und plötzlich geht es nicht mehr! Oft können wir nicht einmal schnell reagieren, denn der Pfad, der zur Entdeckung der Regression geführt hat, ist möglicherweise schwer zu identifizieren. Welcher Nutzer weiß schon noch genau, was er oder sie gemacht hat, bevor dieses ärgerliche Problem aufgetreten ist?
Wir sollten daher die End-to-End-Tests auf diejenigen Funktionen ausrichten, die für unsere Nutzer von kritischer Bedeutung sind. Indem wir diese Funktionen regelmäßig ermitteln, haben wir die Möglichkeit, den Testaufwand auf das notwendige Minimum zu beschränken und gleichzeitig die Relevanz der Tests im Laufe der Zeit aufrechtzuerhalten. Aus dieser Erkenntnis heraus entstand das Usage-Driven Testing.

Usage-Driven Testing – Ein Shift-Right Ansatz
Die Idee des Usage-Driven Testing besteht darin, Verhaltensmuster von Anwendern im laufenden Betrieb zu erkennen, zu analysieren und den Testaufwand gezielt, datenbasiert auf die wichtigen Abläufe zu konzentrieren. Wie in Abbildung 2 dargestellt, handelt es sich um einen „Shift-Right“-Ansatz, da er sich auf das Sammeln und Analysieren von Nutzungsdaten aus der Produktionsphase stützt. Aus den gewonnenen Daten können wir abweichende Nutzungsmuster erkennen und automatisierte Regressionstests generieren. Der gesamte Prozess besteht aus vier Schritten.
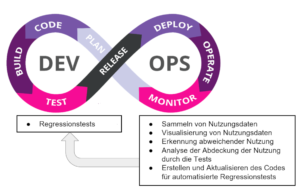
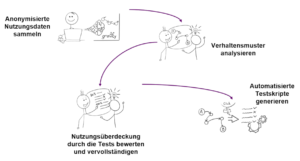
Schritt 1 – Daten erfassen
Nehmen wir das Beispiel eines Java-Script-basierten Webstores. Um Erkenntnisse über die reale Nutzung des Webstores zu erhalten, installieren wir sowohl in der Produktions- als auch in der Testumgebung einen Daten-Kollektor, welcher die Benutzerinteraktionen (Klicks, Ausfüllen von Formularen, …) registriert und erforderliche technische Daten (z. B.
die Bildschirmgröße) aufzeichnet. Letztere werden später benötigt, um die Nutzungs-sitzungen in automatisierten Tests nachzubilden.Was ein wenig nach Überwachung durch Big Brother klingt, ist vollständig transparent. Bei dem Daten-Kollektor handelt es sich um ein Open-Source-Skript, welches nach allen Regeln des Datenschutzes gemäß DSGVO geprüft ist.
Das Skript wird z. B. via npm in das JavaScript-Projekt importiert und mit einer Zeile im Code der Webseite aufgerufen (siehe Abbildung 4). Ab diesem Moment wird es beim Laden der Seite gestartet, wobei ein Authentifizierungsschlüssel eingerichtet wird, der es ermöglicht, verschiedene Datenquellen zu unterscheiden. Tatsächlich sammeln wir Informationen aus zwei Quellen: Neben der Produktivumgebung lassen wir den Daten-Kollektor auch in der Testumgebung laufen. Die Regressions-Tests sollen schließlich ähnliche Abläufe durchführen und prüfen, wie sie in der Realität vorkommen. Um zu bewerten, ob bzw. inwieweit sie das wirklich tun, müssen wir sie vergleichen können.

Schritt 2: Verhaltensmuster analysieren
Die gesammelten Daten enthalten Nutzungssitzungen (Sessions), die aus Sequenzen von Webseiten und Benutzeraktionen auf diesen Webseiten bestehen. Diese können visualisiert werden, wie in Abbildung 5 dargestellt. Jede Spalte entspricht einer Webseite, jeder Block einer Benutzeraktion. Da keine personenbezogenen Informationen wie Nutzername oder Passwort gesammelt wurden, werden sie durch Platzhalter ersetzt.
Diese Ansicht der Sessions ermöglicht es, die tatsächliche Nutzung der Anwendung in der Produktion zu verstehen. Wir können Verhaltensmuster erkennen, also wiederkehrende und
häufig auftretende Abfolgen von Handlungen. Jedes dieser Muster entspricht einer typischen Nutzung (engl. Usage), was dem Ansatz seinen Namen „Usage-Driven Testing“ beschert hat. Entscheidend ist die Ähnlichkeit der Abläufe, denn die wiederkehrenden Muster müssen nicht zwangsläufig streng aufeinanderfolgenden Handlungen entsprechen. Metriken zeigen die Häufigkeit der Nutzung unter allen gesammelten Sitzungen und ermöglichen es, die Nutzungen zu priorisieren, die vorrangig von den Tests überdeckt werden sollen.

Schritt 3: Nutzungsüberdeckung durch die Tests bewerten und vervollständigen
Die Test-Sessions lassen sich auf die gleiche Weise darstellen. Dadurch wird verständlich, was im Test geprüft wird. Nun kommt der Moment der Wahrheit. Wenn eine Nutzung in
17 % der produktiven Sessions identifiziert wurde, im Test jedoch nur 1 % ausmacht, haben wir eine Diskrepanz. Offensichtlich konzentrieren wir uns im Test nicht auf die wirklich relevanten Abläufe.
Schritt 4: Automatisierte Testskripte generieren
Im letzten Schritt nutzen wir die im ersten Schritt erfassten technischen Daten, um Lücken im Test zu schließen. Dazu wählen wir gezielt relevante Sessions aus der Produktivumgebung aus und fügen sie als automatisiert ausführbare Tests der Testdatenbank hinzu. Diese werden schließlich durchgeführt, wodurch sich die gemessene
Nutzungsüberdeckung erhöht. Usage-Driven Testing ermöglicht somit eine gezielte Auswahl aussagekräftiger Tests, die dem gewünschten „notwendigen Minimum“ entsprechen und die als Regressionstests dank ihrer Nähe zur realen Nutzung eine gute Nutzererfahrung gewährleisten.
Werkzeugunterstützung – Gravity und Cypress
Selbstverständlich erfordert Usage-Driven Testing – wie jeder automatisierte Prozess – eine geeignete Werkzeugunterstützung. In unserem Beispiel werden zwei Werkzeuge eingesetzt:
• die SaaS-Anwendung Gravity sowie
• das Testautomatisierungs-Framework Cypress.
Gravity besteht aus zwei Teilen: dem Daten-Kollektor, welcher die tatsächliche Nutzung von Web-Anwendungen im laufenden Betrieb sammelt und einer SaaS-Anwendung, welche die Sessions analysiert, visualisiert, mit bestehenden Testsitzungen vergleicht und die Möglichkeit bietet, ausführbare Testskripte im Cypress-Format zu generieren.
Die Testdurchführung erfolgt in Cypress. Das relativ neue Framework erfreut sich zunehmender Beliebtheit und scheint Selenium im Bereich der Automatisierung von End-to-End-Tests moderner Webanwendungen den Rang abzulaufen.
Beide Werkzeuge sind eng miteinander verwoben. So übernimmt Gravity einen Großteil des Scripting-Aufwands in Cypress, wodurch wir dem erklärten Ziel, schneller zu werden, ein weiteres Stück näherkommen.
Fazit
In diesem Artikel haben wir Usage-Driven Testing vorgestellt – ein „Shift-Right“-Ansatz, bei dem anonymisierte Informationen über die Nutzung gesammelt werden, um
• Diskrepanzen zwischen unseren Erwartungen und der realen Nutzung von Web-Anwendungen im laufenden Betrieb zu erkennen und
• automatisierte End-to-End-Tests zu erstellen, zu bewerten und zu pflegen.
Der Einsatz von Usage-Driven Testing mit den Werkzeugen Gravity und Cypress hat eine Reihe von Vorteilen:
1. Wir erhalten Informationen aus dem laufenden Betrieb und erfahren so, wie die Nutzer tatsächlich agieren.
2. Wir können frühzeitig erkennen, ob bzw. inwieweit die reale Nutzung unseren ursprünglichen Annahmen entspricht.
3. Wir erhalten automatisierte End-to-End-Tests, die widerspiegeln, was die Nutzer wirklich tun und erhöhen somit die Relevanz unserer Tests.
4. Wir können den Code für die Testautomatisierung aus den gesammelten Nutzungsdaten generieren, was den Aufwand für die Erstellung und Pflege der Testskripte verringert.
Weiterführende Informationen
Eine Dokumentation von Cypress ist unter https://docs.cypress.io/guides verfügbar. Darüber hinaus gibt es eine sehr aktive Gemeinschaft von Cypress-Nutzern, die sich über bewährte Praktiken austauschen, um die Nutzung von Cypress zu optimieren.
Gravity ist unter folgender Adresse verfügbar: https://www.gravity-testing.com/
Gravity befindet sich noch in der Entwicklung und das Team würde sich freuen, mit Ihnen als Evaluierungspartner in Deutschland die Lösung zu validieren.

