

Autor: Dr. Michael Mlynarski, Tobias Varlemann und Boris Spivak
Die meisten Ansätze in der Industrie bezogen auf Test-Tools fokussieren die Automatisierung der Testdurchführung. Wir sind hier zu „Weltmeistern“ geworden, was die Breite der verfügbaren Frameworks für die Testautomatisierung betrifft. Häufig wird die Strategie „Automate all that stuff“ angewandt, die oft weder methodisch noch kaufmännisch sinnvoll ist. Gerade im Umfeld von eingebetteten Systemen (wegen der Verfügbarkeit von HW-Ressourcen) oder in cloudbasierten Umgebungen (mit Pay by Usage) ist die permanente Durchführung aller Tests auf Dauer ineffizient. So stellt sich bei einem steigenden Grad der Testautomatisierung die Frage: Wie können die relevanten Tests identifiziert und die Durchführung besser geplant werden?
Die tägliche (bzw. nach jedem Build angesetzte) Durchführung der automatisierten Tests erzeugt eine Datenfülle. Auch die Semantik der Testfälle, der dazugehörigen Testdaten sowie die Testreports halten viele Daten bereit. Darüber hinaus gibt es Artefakte, wie Fehlerberichte (bspw. Tickets in JIRA), Requirements (bspw. Issues in ALM), Code und Commit Logs (bspw. aus gitlab) bis hin zu den Daten der Testumgebungen (bspw. aus Monito- ring-Tools). All diese Datenquellen beinhalten wertvolle Informationen, die genutzt werden können, um die Testdurchführung automatisiert zu planen und so die Nutzung zu optimieren.
EIN LÖSUNGSWEG
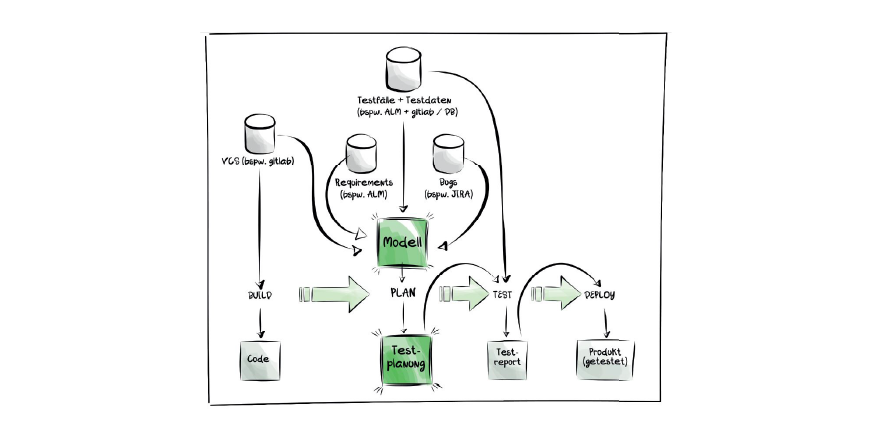
Die Notwendigkeit einer „intelligenten“ Testplanung kann im Grunde nur mit Machine Learning (ML) erfolgreich angegangen werden. Das lässt sich gut mit unseren Projekten bspw. in der Automotive-Branche belegen. Unser Ansatz dabei ist, die vorhandenen Daten (bspw. diverse Testartefakte, Bugs, Requirements, Commits) gezielt mittels ML-Algorithmen dafür zu nutzen, das optimale Testset zu berechnen. Dabei werden sämtliche Daten fürs Training verwendet und mittels Supervised Learning die Algorithmen ständig verbessert. Ein solches Modell kann im Rahmen von CI/CD-Pipelines als Vorstufe der Testdurchführung genutzt werden, um dynamisch zu bestimmen, welche Testfälle im aktuellen Build ausgeführt werden sollten und welche nicht. Die oben stehende Darstellung illustriert diese Grundidee. Die Bestandteile der Lösung:
- Strukturierte Daten aus unterschiedlichen Quellen
- Metadaten insb. Traceability zwischen den Artefakten
- Algorithmen (bspw. Clustering oder Heuristiken bis hin zu neuronalen Netzen)
- Modell (im Sinne von ML bspw. ein trainiertes neuronales Netz)
- CI/CD inkl. Testautomatisierung
KONKRETES BEISPIEL
Der hier dargestellte Lösungsvorschlag basiert auf einem realen Projekt aus der Automotive-Branche. Das konkrete Problem waren die sehr hohen (teilweise rein manuellen) Aufwände für die Planung von übergreifenden Tests rund ums Fahrzeug. Der Kontext war das Embedded Testing von vielen Electronic Control Units (kurz ECUs) mit jeweils 50000+ Testfällen. Diese basierten auf einer strukturierten Spezifikationssprache, die sich jedoch pro ECU unterschieden hat. Unsere Aufgabe war, diese Testfälle (sowie weitere Testdaten, Bug Reports etc.) einzulesen, in eine gemeinsame Struktur zu transformieren, die für ML-Algorithmen nutzbar ist, und mithilfe von dedizierten Algorithmen die Testplanung zu automatisieren. Da die Rohdaten für qualitativ hochwertige Planungen zu Beginn nicht ausreichend waren, haben wir uns für einen Supervised Learning Ansatz entschieden. In der Pilotphase haben mehrere Testmanager mit tiefem Domänen Know-how die automatisiert erstellten Planungsvorschläge bewertet und mit unterschiedlichen Scores kontinuierlich verbessert. Unterstützend haben wir eine besondere Art der Usability für komplexe Datendarstellungen untersucht und umgesetzt.
HERAUSFORDERUNGEN
1. Data Structures & Pre-Processing
In den meisten Fällen sind die Datenstrukturen von Testfällen, Testdaten, Testlogs, Bugs etc. nicht darauf ausgerichtet, diese für ML zu nutzen. So erzielt man bspw. den größten Erfolg dann, wenn alle Testfälle derselben Syntax und Semantik folgen. Doch bereits in einem Projekt kann es mehrere Beschreibungssprachen (bspw. für Unit, Integration, System oder UAT) geben. Schwierigkeiten bereiten auch die fehlenden Referenzen zwischen den Datensätzen (bspw. automatisierter Testfall Requirements Code Commit und ggf. Bug ID). Oft müssen die Daten in eine einheitliche Struktur transformiert und ggf. mit Metadaten angereichert werden, um diese im Trainingsprozess überhaupt nutzen zu können. Ein solcher „Pre-Processing“-Schritt auf dem Weg zu einem antrainierten Modell kann mehr als die Hälfte der geplanten Zeit eines solchen Projektes einnehmen (im konkreten Fall waren es sogar 60 % der Zeit).
2. UX für Testplanungs-Dashboards
Damit der antrainierte ML-Algorithmus Nutzen bringen kann, bedarf es einer aussagekräftigen und leicht bedienbaren Benutzeroberfläche. Mit unserer Lösung wollten wir die identifizierten Zusammenhänge zwischen einzelnen Testfällen visualisieren sowie intuitive Steuerelemente für das Supervised Learning anbieten. In unserem Beispiel hat das System die als passend identifizierten Testfälle in einer Liste geliefert. Diese konnte nach bestimmten Kriterien sortiert werden, u. a. nach Anzahl erkannter Verbindungen zu anderen Testfällen sowie nach Fehlerhäufigkeiten. Auch wurden die Tests nach semantischen Bestandteilen gruppiert. Für jeden Testfall bestand die Möglichkeit, durch einen Like/Dislike dem Algorithmus Feedback zu geben, ob die vorgeschlagenen Testfälle tatsächlich ausgeführt werden sollen. Für ein vereinfachtes Reporting entwickelten wir ein Dashboard mit unterschiedlichen Diagrammen zu den definierten Qualitätsmetriken. Diese Informationen wurden grafisch durch Balken-, Sunburst- und Icicle-Diagramme angezeigt, wofür die Java- Script-Bibliothek zum Einsatz kam (https://d3js.org/). Mithilfe von Unreal Engine wurden Verbindungen zwischen einzelnen Komponenten am virtuellen Fahrzeug zusätzlich in einer VR-Umgebung dreidimensional visualisiert. So konnten wir mehr Transparenz in den Testdatenbestand bringen und Werkzeuge anbieten, mit denen sich die Testplanung maßgeblich vereinfachen ließ.
3. Datenqualität
Eine der wichtigsten Herausforderungen ist außerdem die Qualität der Daten, die als Grundlage für ML verwendet werden. Das ist normalerweise die Domäne von spezialisierten Rollen, wie etwa dem Data Scientist oder Data Analyst. Neben dem Pre-Processing ist erstens eine ausreichende Menge an Daten, zweitens unterschiedliche Varianten der Daten enorm wichtig, um bspw. Over- oder Underfitting-Effekte im Falle von neuronalen Netzen zu vermeiden. Unsere klare Empfehlung ist hier, die Daten basierend auf Methoden aus dem Bereich Data Science im Vorfeld anzuwenden; angefangen bei der statistischen Verteilung von Objekten bis hin zu semantischen Clustern.
FAZIT
Digitalisierung im Sinne von ML kann sehr vorteilhaft für das Software-Testing sein; die Daten, die dazu benötigt werden, sammeln wir täglich in unseren Projekten. Um diese sinnvoll zu nutzen, braucht es mehr Auseinandersetzung mit der Struktur dieser Daten und Algorithmen (von Clustering, linearer Regression bis hin zu neuronalen Netzen), die für bestimmte Problemstellungen mehr oder weniger besser geeignet sind. Basierend auf den Erfahrungen aus unseren Projekten sind wir uns sicher, dass der Trend künftig hin zur „intelligenten“ Testplanung führen wird und wir deutlich stärker unsere Daten nutzen sollten.
Bitte melden Sie sich an oder erstellen Sie ein Konto, um diesen Inhalt weiter zu lesen.

