


Autor:innen: Barbara Faulstich und Julius Höhn
„Garbage in, garbage out“ – Dieses grundlegende Programmierprinzip verdeutlicht eindrücklich, dass die Qualität der Eingabedaten entscheidend für den Erfolg von KI-Systemen in der öffentlichen Verwaltung ist. Künstliche Intelligenz (KI) verspricht erhebliche Effizienz- und Effektivitätssteigerungen, erfordert jedoch eine fundierte Datenintegration und -verarbeitung. Diese Aspekte sind entscheidend, um das Potenzial der KI voll auszuschöpfen, während gleichzeitig ethische und datenschutzrechtliche Bedenken sorg-fältig adressiert werden müssen.
Datenmanagement in Behörden
Effektives Datenmanagement ist entscheidend für den Erfolg von KI-Operationen in Behörden. Die Vielfalt der Datenquellen – von statistischen Ämtern über Forschungsinstitute bis hin zu Umfragen und Unternehmenspartnerschaften – erfordert eine robuste Datenerhebung und -verarbeitung. Die Herausforderungen sind enorm, wie das Beispiel von Amazons KI-Bewerbungssystem zeigt, das aufgrund fehlerhafter Daten weibliche Bewerberinnen aussortierte.
Ein besonders herausforderndes Beispiel ist Predictive Policing, wie das „PredPol“-System in US-Städten zeigt. Hier besteht die Schwierigkeit darin, sicherzustellen, dass die Daten repräsentativ und vorurteilsfrei sind, um eine unverhältnismäßige Überwachung bestimmter Bevölkerungsgruppen zu vermeiden.
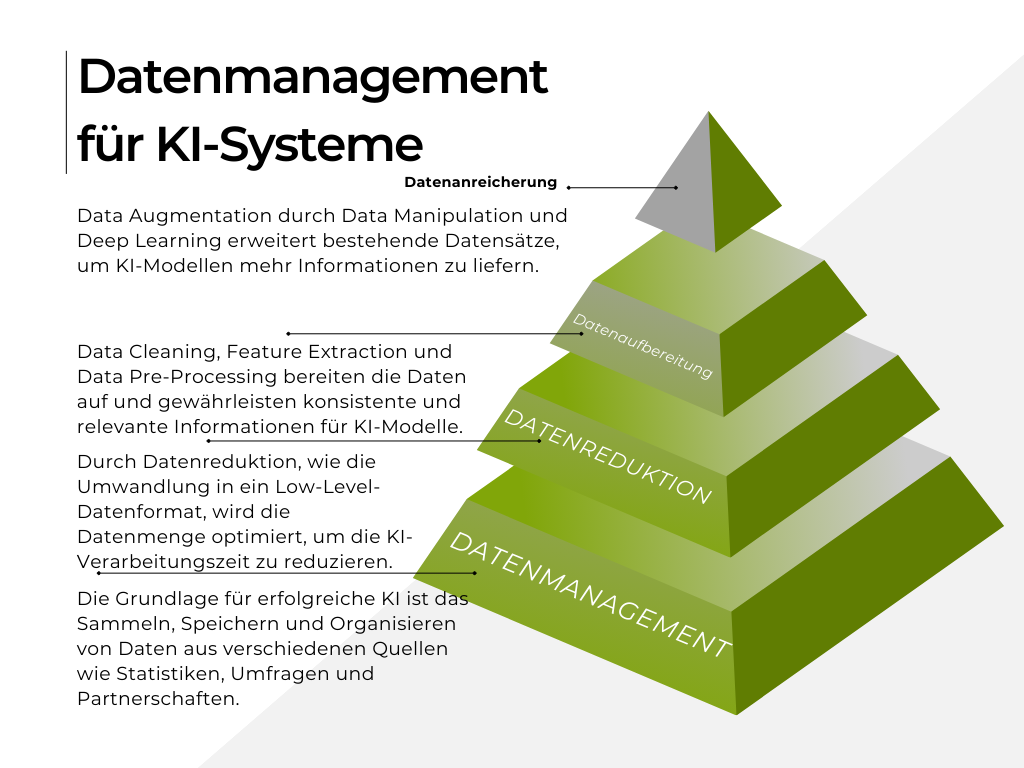
Abb. 1 Darstellung des aktuellen Datenmanagements in Behörden
Ein weiteres Beispiel ist die KI-gestützte Erkennung von Sozialleistungsbetrug in Großbritannien. Das Department for Work and Pensions (DWP) ana-lysiert zahlreiche Datenpunkte, wobei die Genauigkeit und der Datenschutz höchste Priorität haben, um unschuldige Personen nicht fälschlicherweise zu verdächtigen.
Auch die Optimierung des öffentlichen Nahverkehrs stellt eine Herausforderung dar, da Daten von Verkehrsbetrieben, Sensoren, Wetterdaten und Bürgerfeedback integriert werden müssen. Diese Datenintegration ist komplex und erfordert sorgfältige Validierung und Konsistenzprüfung.
Im Vergleich zur freien Wirtschaft müssen Behörden strenge Datenschutzbestimmungen einhalten und eine hohe Transparenz und Rechenschaftspflicht gewährleisten, was die Datenerhebung und -verarbeitung weiter erschwert. Unternehmen können flexibler und schneller auf neue Technologien reagieren und haben weniger bürokratische Hürden.
Herausforderungen im Umgang mit KI
Die Einführung von KI stellt Behörden vor mehrere Herausforderungen: von der Datenerhebung und Datenkennzeichnung (Data Labeling) über die Datenaufbereitung (Data Reparation) und Datenreduktion bis hin zur Datenanreicherung (Data Augmentation). Jeder Schritt ist entscheidend, um sicherzustellen, dass die Datensätze aktuell, relevant und aussagekräftig sind, sodass sie zuverlässige Ergebnisse durch KI-Systeme liefern können. Mitarbeiter:innen müssen sich an neue Arbeitsweisen und Technologien an-passen. Transparenz und Vertrauen spielen hierbei eine zentrale Rolle.
Behörden müssen transparente KI-Modelle verwenden, um das Ver-trauen der Bürger zu gewinnen. Erklärbarkeit und Nachvollziehbarkeit der KI-Entscheidungen sind dafür entscheidend. Die Datenaufbereitung (Data Reparation) ist ein kritischer Schritt, der eine sorgfältige Überprüfung und Bereinigung der Daten erfordert.
Unreine oder fehlerhafte Daten können zu unzuverlässigen Modellen führen. Darüber hinaus müssen die Daten repräsentativ sein und die Vielfalt der realen Welt widerspiegeln, um Verzerrungen zu vermeiden. Beispielsweise sollten Kriminalitätsdaten, die für ein KI-Modell verwendet werden, verschiedene Stadtteile und Arten von Verbrechen abdecken. Auch die Auswahl relevanter Merkmale und die Transformation von Rohdaten (Feature Engineering) sind wichtige Schritte, um aussagekräftige Daten zu gewährleisten. Die Datenreduktion ist notwendig, um die Effizienz der KI-Systeme zu steigern. Große Datensätze können zu langen Trainingszeiten führen, weshalb die Reduktion der Anzahl der Merkmale durch Dimensionalitätsreduktionstechniken wie Principal Component Analysis (PCA) oder t-Distributed Stochastic Neighbor Embedding (t-SNE) sinnvoll ist.
Effiziente Stichprobenverfahren helfen dabei, die Datenmenge zu verringern, ohne wichtige Informationen zu verlieren. Beispielsweise kann eine Behörde bei der Analyse von Steuerdaten irrelevante Merkmale entfernen, um die Verarbeitungszeit zu verkürzen.
Die Datenanreicherung (Data Augmentation) umfasst die Generierung zusätzlicher Datenbeispiele, um den Mangel an Trainingsdaten zu kompensieren. Synthetische Daten können hierbei eine wichtige Rolle spielen und die Modellleistung verbessern. Eine Behörde, die ein KI-Modell zur Verkehrsflussvorhersage entwickelt, kann beispielsweise synthetische Verkehrsdaten generieren, um die Modellleistung zu steigern. Dabei ist es wichtig, Domainwissen zu nutzen, um sicherzustellen, dass die generierten Daten realistisch und relevant sind. Insgesamt erfordert die Integration von KI in Behörden eine ganzheitliche Betrachtung, die sowohl technische als auch organisatorische und ethische Aspekte berücksichtigt. Nur durch eine sorgfältige Planung und Umsetzung in diesen Bereichen kann sichergestellt werden, dass KI-Systeme zuverlässige und vertrauenswürdige Ergebnisse liefern.
Strategien für Datenintegration und Datenmanagement
Um KI effektiv in die öffentliche Verwaltung zu integrieren, sind strategisch fundierte Methoden für die Datenintegration und -verarbeitung erforderlich. Technologien wie Informatica PowerCenter und IBM InfoSphere sind dabei unverzichtbar, da sie eine umfassende Datenintegration ermöglichen, während Tools wie Trifacta und Alteryx eine entscheidende Rolle beim Datenqualitätsmanagement spielen.
Informatica PowerCenter ist eine Platt-form für Datenintegration, die den ETL-Prozess (Extrahieren, Transformieren, Laden) unterstützt. Sie ist skalierbar, benutzerfreundlich und kann große Datenmengen aus verschiedenen Quellen verarbeiten. Ihre besondere Stärke liegt in der effizienten Integration heterogener Datenquellen und ihrer robusten Architektur für hohe Leistung und Zuverlässigkeit.
IBM InfoSphere ist eine umfassende Suite für Datenintegration, -qualität und -verwaltung. Sie bietet leistungsstarke ETL-Funktionen, verbessert die Datenqualität durch Bereinigung und Validierung und unterstützt umfassende Daten-Governance. InfoSphere zeichnet sich durch seine Funktionen zur Datenkatalogisierung und -klassifizierung aus und bietet eine ganzheitliche Sicht auf den Datenlebenszyklus.
Zusammen bieten Informatica PowerCenter und IBM InfoSphere robuste und skalierbare Lösungen für die Datenintegration und das Datenmanagement, die für die effiziente Nutzung von Daten in der öffentlichen Verwaltung unerlässlich sind.
Anwendungsfälle
Use Case 1: Fehlerdiagnose in KI-Systemen
Die Fehlerdiagnose in KI-Systemen ist entscheidend, um die Effizienz und Qualität in verschiedenen Anwendungsbereichen zu verbessern. Moderne Systeme sind zunehmend komplexer, was das Fehlermanagement erschwert. Künstliche Intelligenz (KI) bietet hier wertvolle Unterstützung, um Fehler frühzeitig zu erkennen und zu beheben.
Ein wichtiger Ansatz zur Fehlerdiagnose ist die Kombination von domänenspezifischem Wissen mit KI-Erkenntnissen. Dies ermöglicht es, Fehlerursachen präzise zu identifizieren und Lösungen effizient zu implementieren.
Funktionsweise der Fehlerdiagnose
Die Fehlerdiagnose beginnt mit der Datenvorverarbeitung, bei der Daten bereinigt werden, um Rauschen und Ausreißer zu entfernen, und fehlende Werte ergänzt werden. Eine hohe Datenqualität ist unerlässlich, um genaue Muster und Trends zu erkennen. Nach der Datenvorverarbeitung erfolgt die Auswahl relevanter Merkmale, auch bekannt als Feature Selection. Hierbei werden diejenigen Variablen identifiziert, die den größten Einfluss auf die Modellleistung haben, was die Komplexität des Modells reduziert und die Interpretierbarkeit verbessert.
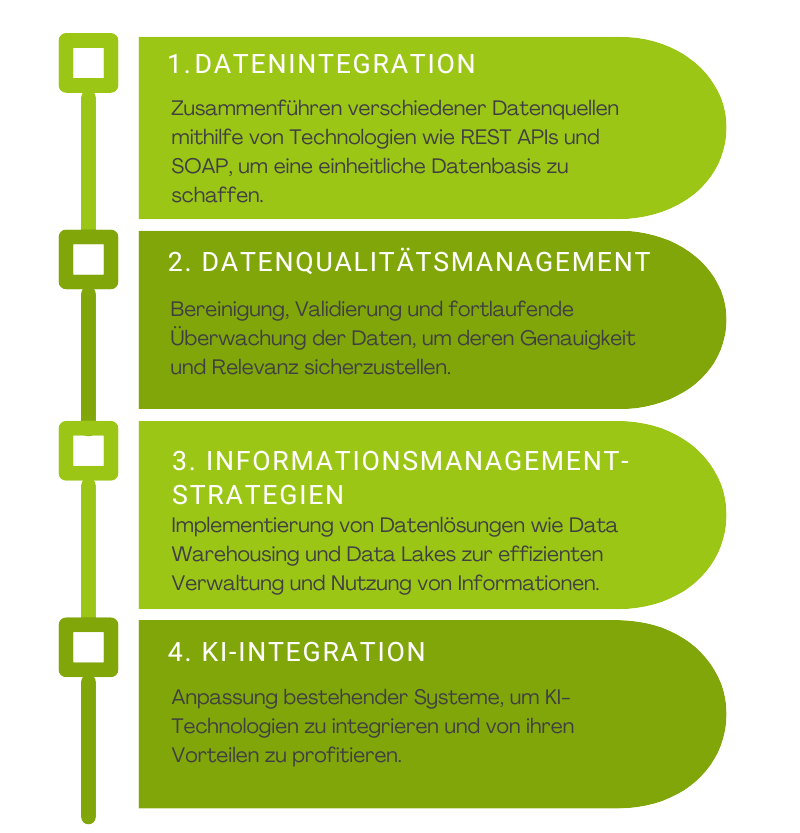
Abb. 2 Flussdiagramm
Im nächsten Schritt werden verschiedene Modelle erstellt und validiert. Dies kann maschinelles Lernen, wie Entscheidungsbäume und neuronale Netze, oder statistische Modelle, wie Regressionsanalysen, umfassen. Ziel ist es, ein Modell zu finden, das die Daten am besten beschreibt und Vorhersagen mit hoher Genauigkeit trifft. Data Mining-Techniken werden eingesetzt, um Muster und Anomalien in den Daten zu erkennen, die auf Fehler hinweisen können. Predictive Analytics nutzt diese Muster, um zukünftige Ereignisse vorherzusagen. Dies ermöglicht es, proaktive Maßnahmen zu ergreifen, bevor Fehler tatsächlich auftreten, und trägt zur Vermeidung größerer Ausfälle bei.
Data Mining und Predictive Analytics
Beim Einsatz von Data Mining und Predictive Analytics müssen verschiedene Aspekte beachtet werden. Eine hohe Datenqualität ist entscheidend, da fehlerhafte oder unvollständige Daten zu falschen Vorhersagen und Diagnosen führen können. Feature Engineering, also die Auswahl und Transformation relevanter Merkmale, maximiert die Modellgenauigkeit. Die Wahl des geeigneten Algorithmus ist ebenfalls wichtig, da verschiedene Modelle je nach Anwendungsfall unterschiedliche Ergebnisse liefern können. Eine gründliche Validierung der Modelle ist unerlässlich, um sicherzustellen, dass sie nicht überangepasst sind und auf neuen Daten zuverlässig funktionieren. Techniken wie Cross-Validation, bei der das Modell auf verschiedene Datensätze getestet wird, und Bootstrapping, welches die Genauigkeit der Vorhersagen durch wiederholtes Zufallsstichprobenziehen aus den Daten verbessert, sind hierbei hilfreich. Modelle sollten zudem transparent und interpretierbar sein, um die zugrunde liegenden Muster zu verstehen und die Vorhersagen erklären zu können. Schließlich müssen die Methoden und Technologien skalierbar sein, um mit großen Datenmengen und hohen Verarbeitungsgeschwindigkeiten umgehen zu können, ethischen Standards entsprechen und den Datenschutzvorschriften gerecht werden.
Beispiele für die Anwendung der Fehlerdiagnose
Produktionsprozesse
In der Produktionsindustrie analysieren Unternehmen historische Produktionsdaten, um Ausfallzeiten vorherzusagen. Gesammelte Daten aus Maschinen und Sensoren werden in einer zentralen Datenbank gespeichert und regelmäßig bereinigt. Wichtige Merkmale wie Maschinentemperaturen, Vibrationen und Betriebsstunden werden identifiziert, um die Modellkomplexität zu reduzieren. Ein maschinelles Lernmodell wird trainiert, um Muster zu erkennen, die auf potenzielle Ausfälle hinweisen. Dadurch können Unternehmen Wartungsarbeiten proaktiv planen und ungeplante Ausfälle minimieren, was zu höherer Effizienz und geringeren Kosten führt.
Gesundheitswesen
In Krankenhäusern und Kliniken kann KI genutzt werden, um Fehler in der Medizintechnik frühzeitig zu erkennen. Beispielsweise können Daten von medizinischen Geräten kontinuierlich überwacht werden, um Anomalien zu identifizieren, die auf bevorstehende Geräteausfälle oder Fehlfunktionen hinweisen. Dies ermöglicht eine rechtzeitige Wartung und den Austausch von Geräten, bevor kritische Fehler auftreten.
Energieversorgung
Im Energiesektor werden große Datenmengen von Sensoren in Stromnetzen und Kraftwerken analysiert, um potenzielle Fehlerquellen zu identifizieren. Predictive Analytics kann hier helfen, Wartungsarbeiten zu optimieren und die Zuverlässigkeit der Energieversorgung zu erhöhen, indem es frühzeitig auf Anzeichen von Störungen oder Ineffizienzen hinweist.
Zusammenfassend lässt sich sagen, dass die Fehlerdiagnose in KI-Systemen durch Data Mining und Predictive Analytics ein leistungsfähiges Werkzeug ist, das zur Verbesserung der Zuverlässigkeit und Effizienz in verschiedenen Branchen beiträgt. Durch sorgfältige Datenvorverarbeitung, Modellbildung und Validierung können Fehler frühzeitig erkannt und behoben werden. Dies optimiert Prozesse und verbessert die Qualität der Dienstleistungen in komplexen Systemen.
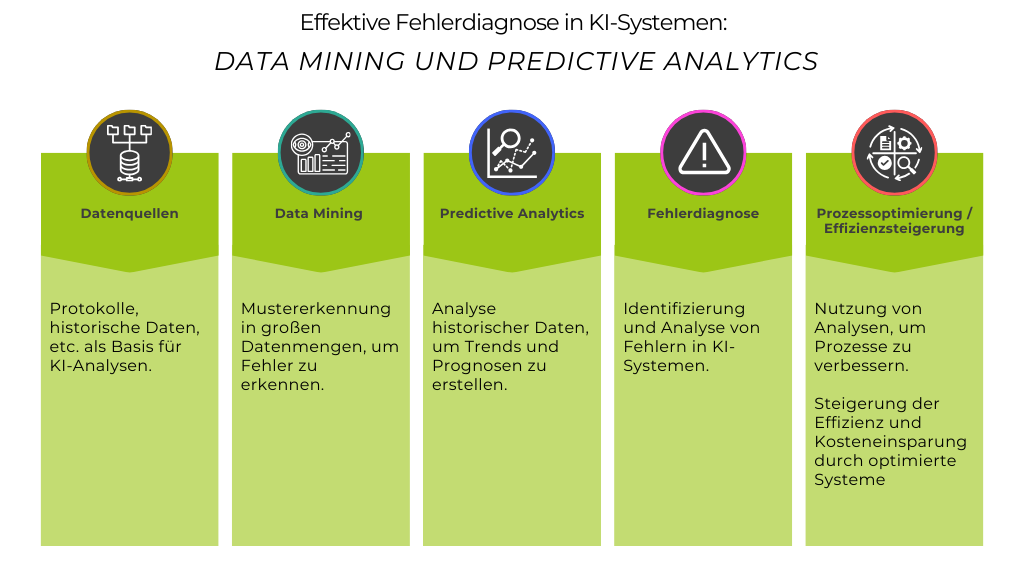
Abb. 3 Use Case 1: Datenmanagement für KI-Systeme
Use Case 2: Datenqualität für Entscheidungsfindung
Eine hohe Datenqualität ist essenziell, um fundierte Entscheidungen in der öffentlichen Verwaltung treffen zu können. Der Einsatz von KI zur Verarbeitung von Daten aus verschiedenen Quellen erhöht die Genauigkeit der Analysen, was zu einer effizienteren und rechtlich einwandfreien Nutzung führt.
Herausforderungen bei der Datenintegration
Die Integration von Daten in KI-Projekte erfordert tiefgreifende Überlegungen und Anpassungen in der technischen Infrastruktur. Die Standardisierung von Datenformaten und die Entwicklung interoperabler Schnittstellen sind nur einige der technischen Herausforderungen. Zudem müssen KI-Systeme Datenschutzvorgaben einhalten, was den Einsatz von Anonymisierungs- und Pseudonymisierungstechnologien notwendig macht.
Einblick in aktuelle Anwendungen zeigt, dass die Einhaltung der DSGVO und die Sicherstellung der Anonymität und Pseudonymität entscheidende Faktoren in Softwareentwicklungsprojekten sind. Beispielsweise werden in Projekten, die künstlich generierte Daten und Testdaten verwenden, täglich automatisierte Konsistenzchecks und Validierungstools eingesetzt. Diese Ansätze sind revolutionär und bereits implementiert, wobei externe Dienstleister oft zur Qualitätssicherung herangezogen werden.
Weiterhin zeigen Erfahrungen, dass die Datenqualität durch regelmäßige Datenbereinigung und manuelle Überprüfungen durch Expert:innen gewährleistet wird, um präzise Entscheidungsunterstützung für Mitarbeiter:innen zu bieten. Diese Praktiken, zusammen mit der Verarbeitung von realweltlichen Nutzerdaten in Business Intelligence Software, unterstreichen die Notwendigkeit einer kontinuierlichen Datenaktualisierung und Überwachung.
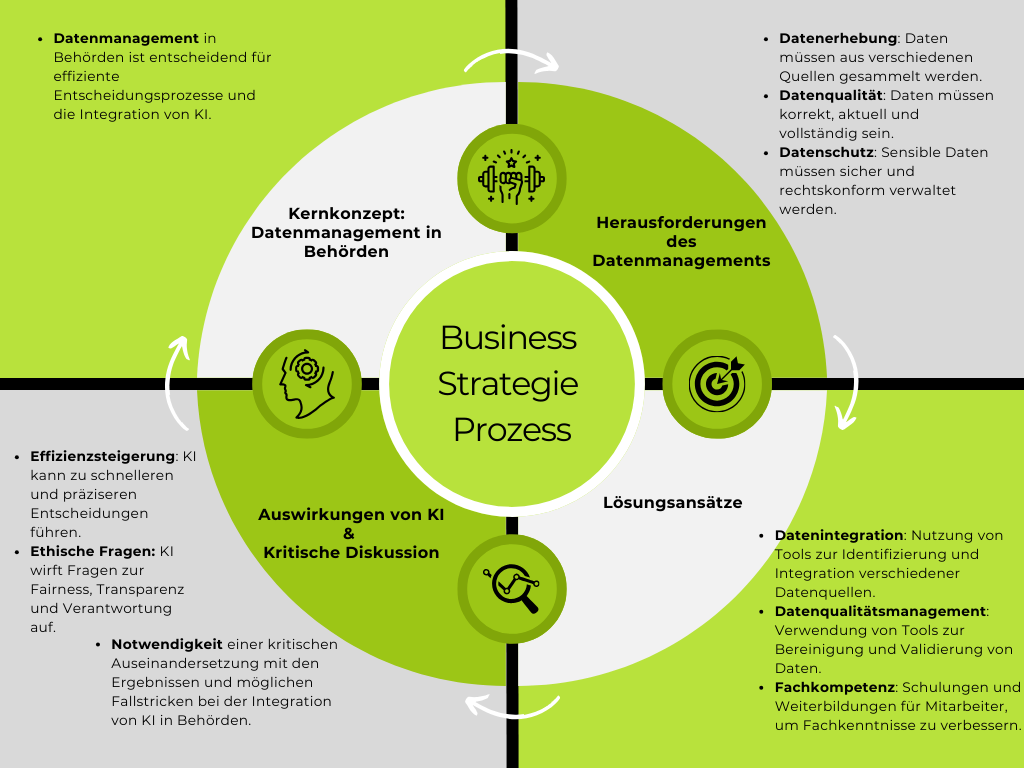
Abb. 4 Diskussion: Datenmanagement in Behörden – Herausforderungen und Lösungsansätze
Die Herausforderungen der Datenintegration umfassen auch die kontinuierliche Anpassung an rechtliche Anforderungen und die Optimierung von Datenverarbeitungsprozessen, um die Effektivität von KI-Systemen zu maximieren und datengetriebene Entscheidungen in Echtzeit zu unterstützen. Zudem müssen KI-Systeme Datenschutzvorgaben einhalten, was den Einsatz von Anonymisierungs- und Pseudonymisierungstechnologien notwendig macht.
Fazit
Die Einführung von KI in der öffentlichen Verwaltung bietet transformative Möglichkeiten, erfordert jedoch eine sorgfältige Abwägung von Chancen und Risiken. Die fortlaufende Qualifizierung des Personals und die ständige Anpassung der Technologien und Methoden an die neuesten Standards sind unerlässlich, um die Integrität, Sicherheit und Effizienz der KI-Systeme zu gewährleisten.

