

Autorin: Anne Kramer
Seit Langem schon unterstützen Mustererkennungsverfahren Mediziner bei der Diagnose. Diese Verfahren basieren auf fest programmierten Algorithmen mit vorab definierten Regeln, was zwar zu guten Ergebnissen führt, in der Regel jedoch langwierig zu programmieren ist. Nun gibt es Deep Learning-Verfahren, bei denen das System zunächst mit Trainingsdaten angelernt wird. Wir sagen der künstlichen Intelligenz (KI), welches Bild Auffälligkeiten zeigt und welches nicht. Im Produktivbetrieb lassen wir KI dann die antrainierten Auswertungsverfahren auf neue Untersuchungsergebnisse anwenden. Diese Vorgehensweise besticht durch ihre Effizienz, stellt allerdings die Qualitätssicherung vor neue Herausforderungen.
TESTDATEN FÜR KI SIND RAR
Zu den guten Praktiken im Machine Learning gehört, Trainingsdaten und Validierungsdaten sauber zu trennen. Während die Trainingsdaten dazu verwendet werden, den Algorithmus anzulernen, dienen die Validierungsdaten für den Test. Beide Datenpools müssen streng getrennt werden, denn sonst können wir das Testergebnis blind vorhersagen. Die Trainingsdaten werden immer „passed“ ergeben, denn genau das hat die KI ja gelernt. Wenn Testdaten nicht oder nur schwer künstlich erzeugt werden können, muss auf reale Daten zurückgegriffen werden. Jeder, der schon einmal Testdaten für diagnostische Software zusammenstellen musste, weiß um die damit verbundenen Schwierigkeiten. Zum einen müssen die Daten anonymisiert werden. Zum anderen sollen sie hinsichtlich der Krankheitsbilder, Patienteneigenschaften (Alter, Geschlecht, Gewicht …) repräsentativ sein. Bei einer KI kommt noch erschwerend hinzu, dass es zum „Bias“- Effekt kommen kann. Es ist daher unter Umständen schon schwierig, eine ausreichende Anzahl an Trainingsdaten zu bekommen. Umso glücklicher sind wir Tester, wenn schließlich sogar Validierungsdaten vorliegen.
ÄNDERUNGEN IM ALGORITHMUS DER KI
Und dann kommt es: Das Update des Algorithmus. Die Magie des Deep Learnings wird erneut angestoßen und plötzlich kommen völlig neue Ergebnisse heraus. In einem unserer Projekte hatte sich die Sensitivität des Algorithmus geändert. Krankes Gewebe wurde erst ab einem höheren Schwellwert erkannt. Systemtestfälle, die im letzten Testlauf noch vollkommen in Ordnung waren, schlugen im Regressionstest fehl. Wir mussten warten, bis neue Validierungsdaten zur Verfügung standen. Dabei ging es bei unseren Tests gar nicht um den Algorithmus an sich, sondern um die Funktionen ”drumherum”, also die Anzeige, das Abspeichern etc. … Daher war es auch nicht offensichtlich, dass unsere Tests von der Änderung betroffen sein würden. Aus Problemen soll man ja bekanntlich lernen. Folgende Ideen könnten sich als hilfreich erweisen:
- Stellen Sie einen Verantwortlichen für die Verwaltung der Testdaten ab (oder ein), der sich hauptsächlich um dieses Thema kümmert und nicht – wie der Product Owner – noch jede Menge andere Aufgaben erfüllen muss. Damit vermeiden Sie einen kritischen Flaschenhals im Projekt.
- Verankern Sie im Änderungsmanagement neben der Frage, ob die Änderungen Einfluss auf die Testfälle haben, ganz explizit auch die Frage, ob Testdaten betroffen sein könnten. Denken Sie dabei auch an die Systemtests.
- Verankern Sie die Bereitstellung der Testdaten in der „Definition of Done“ des Algorithmus.
ALTERUNGSEFFEKTE
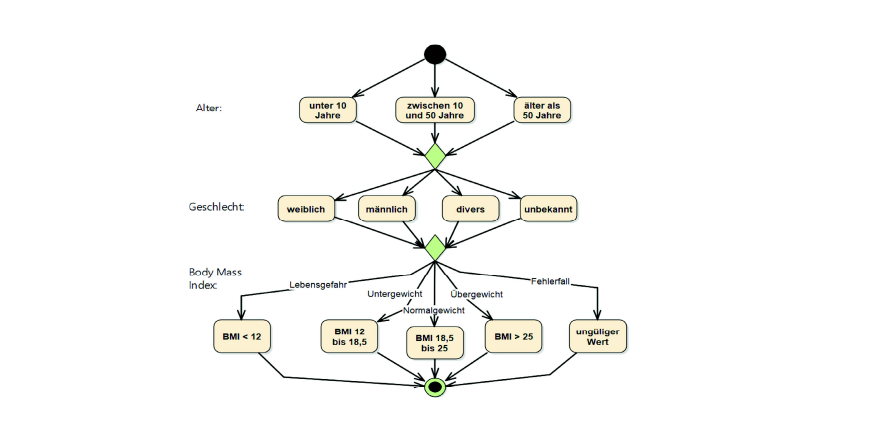
Auch ohne KI ist das Änderungsmanagement von Testdaten eine Herausforderung. Oftmals nimmt die Qualität der Testdaten über die Zeit hinweg ab. Der erste Datenpool ist noch sehr repräsentativ. Dann wird ein neuer Parameter eingeführt. Ist dieser optional, bleiben die bestehenden Testdaten weiterhin gültig. Es werden nur ein paar Datensätze geändert, um den optionalen Parameter zu prüfen. Das führt jedoch dazu, dass bei 99 % der Testdaten besagter Wert nie gesetzt ist. Ist der Parameter zwingend erforderlich, müssen alle Testdaten angepasst werden. Erneut ist der Weg des geringsten Widerstandes verlockend. Man setzt in einigen Testfällen die verschiedenen Äquivalenzklassen für den neuen Parameter ein und füllt die verbleibenden Datensätze mit einem gültigen Wert auf. Auch hier haben wir bei 99 % der Testdaten den gleichen Wert. Wir setzen an dieser Stelle auf Datenmodellierung. Die Kombinatorik der Äquivalenzklassen lässt sich gut grafisch darstellen, wie Abb. 1 schematisch zeigt. Kombiniert man die Äquivalenzklassen in Abb. 1 geschickt, kommt man mit 5 Datensätzen aus. Ändert sich etwas im Modell, können wir einen neuen, optimalen Satz an Testdaten erzeugen. Dadurch erhöhen wir die Varianz der Tests und wiederholen nicht zwangsläufig in jedem Sprint identische Tests. Bei passender Werkzeugunterstützung – in unserem Fall durch die MBTsuite – erhalten wir diesen minimalen Satz an Testdaten automatisiert per Knopfdruck.
AUSBLICK
Generell können wir davon ausgehen, dass der Test in Zukunft noch reaktiver sein und stärker in bestehende Prozesse eingebunden werden muss. Ein wichtiger Treiber ist das Internet der Dinge (IoT). Im „ASQF® Certified Professional for IoT“ wird für IoT eine weitere Teststufe gefordert: der Test im Betrieb. Ganz im Sinne der DevOps- Philosophie sollten wir in Zukunft zu einer organisatorischen Einheit oder zumindest zu einem gut geregelten Zu- sammenspiel zwischen Test in der Entwicklung und Rückmeldung aus dem laufenden Betrieb kommen.
Bitte melden Sie sich an oder erstellen Sie ein Konto, um diesen Inhalt weiter zu lesen.

